publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- CHILD (Controller for Humanoid Imitation and Live Demonstration): a Whole-Body Humanoid Teleoperation SystemNoboru Myers, Obin Kwon, Sankalp Yamsani, and Joohyung KimIn 2025 IEEE-RAS 24th International Conference on Humanoid Robots (Humanoids), 2025TeleoperationHumanoid
- PAPRLE (Plug-And-Play Robotic Limb Environment): A Modular Ecosystem for Robotic LimbsObin Kwon, Sankalp Yamsani, Noboru Myers, Sean Taylor, Jooyoung Hong, Kyungseo Park, Alex Alspach, and Joohyung KimIn arXiv, Jul 2025TeleoperationManipulation
2024
-
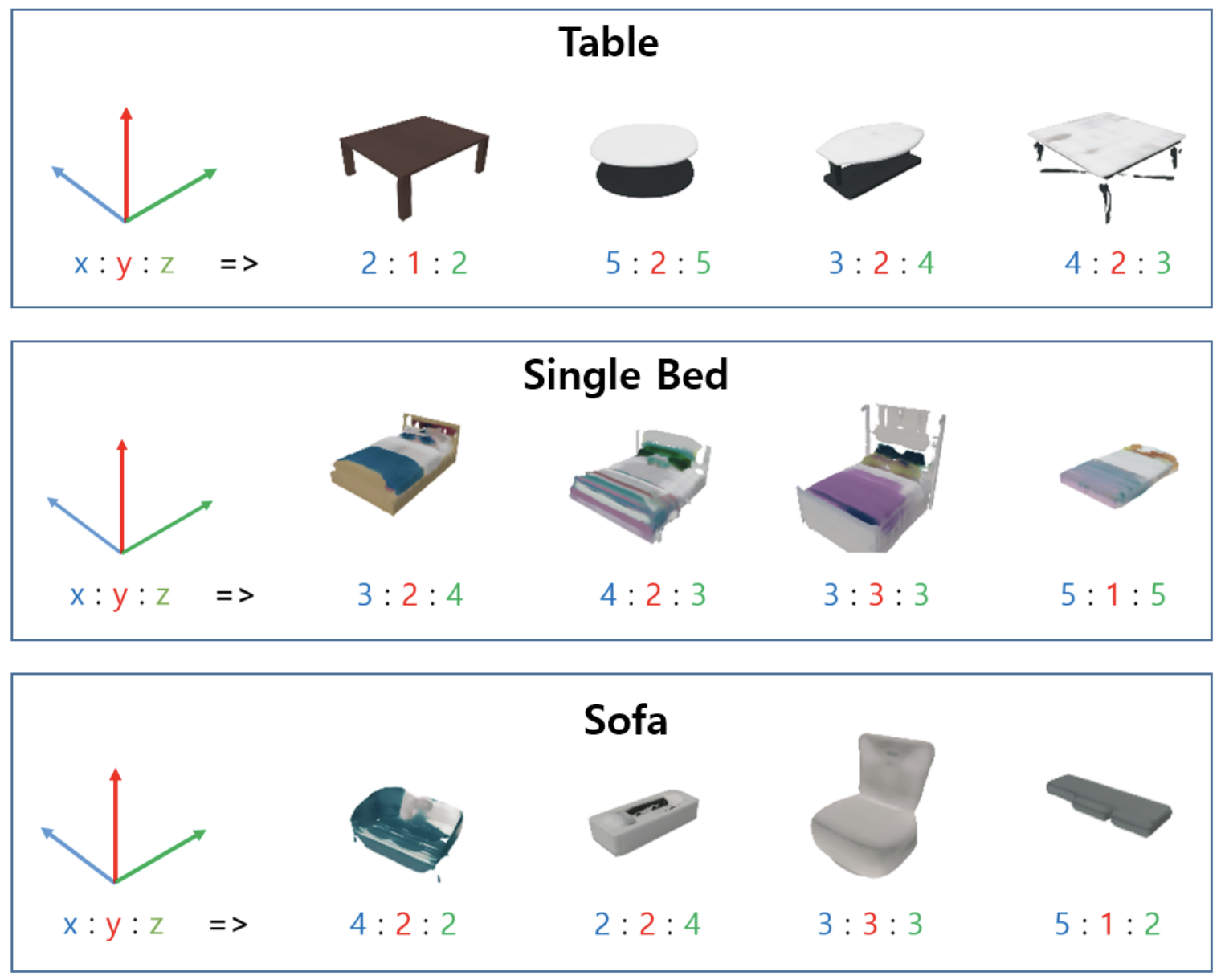 Spatially-Conditional 3D Furniture Generation Model for Indoor Scene GenerationJeongho Park, Obin Kwon, and Songhwai OhIn 2024 24th International Conference on Control, Automation and Systems (ICCAS), Oct 2024Scene RepresentationScene Generation
Spatially-Conditional 3D Furniture Generation Model for Indoor Scene GenerationJeongho Park, Obin Kwon, and Songhwai OhIn 2024 24th International Conference on Control, Automation and Systems (ICCAS), Oct 2024Scene RepresentationScene Generation - RNR-Nav: A Real-World Visual Navigation System Using Renderable Neural Radiance MapsMinsoo Kim, Obin Kwon, Howoong Jun, and Songhwai OhIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024 (Oral Presentation)Scene RepresentationVisual NavigationVisual LocalizationNeRF
We propose a novel visual localization and navigation framework for real-world environments, utilizing a mapping method that directly integrates observed visual information into the bird-eye-view map. While the renderable neural radiance map (RNR-Map), a grid map consisting of visual information represented as latent codes at each grid, shows considerable promise in simulated settings, its deployment in real-world scenarios poses undiscovered challenges. RNR-Map utilizes projections of multiple vectors into a single latent code, resulting in information loss under suboptimal conditions. To address such issues, our enhanced RNR-Map for real-world robots, RNR-Map++, incorporates strategies to mitigate information loss, such as a weighted map and positional encoding. For robust real-time localization, we integrate a particle filter into the correlation-based localization framework using RNRMap++ without a rendering procedure. Consequently, we establish a real-world robot system for visual navigation utilizing RNR-Map++, which we call “RNR-Nav.” Experimental results demonstrate that the proposed methods significantly enhance rendering quality and localization robustness compared to previous approaches. In real-world navigation tasks, RNR-Nav achieves a success rate of 84.4%, marking a 68.8% enhancement over the methods of the original RNR-Map paper.
- WayIL:Image-based Indoor Localization with Wayfinding MapsObin Kwon, Dongki Jung, Youngji Kim, Soohyun Ryu, Suyong Yeon, Songhwai Oh, and Donghwan LeeIn 2024 International Conference on Robotics and Automation (ICRA), May 2024Scene RepresentationVisual Localization
This paper tackles a localization problem in large-scale indoor environments with wayfinding maps. A wayfinding map abstractly portrays the environment, and humans can localize themselves based on the map. However, when it comes to using it for robot localization, large geometrical discrepancies between the wayfinding map and the real world make it hard to use conventional localization methods. Our objective is to estimate a robot pose within a wayfinding map, utilizing RGB images from perspective cameras. We introduce two different imagination modules which are inspired by how humans can comprehend and interpret their surroundings for localization purposes. These modules jointly learn how to effectively observe the first-person-view (FPV) world to interpret bird-eye-view (BEV) maps. Providing explicit guidance to the two imagination modules significantly improves the precision of the localization system. We demonstrate the effectiveness of the proposed approach using real-world datasets, which are collected from various large-scale crowded indoor environments. The experimental results show that, in 85% of scenarios, the proposed localization system can estimate its pose within 3m in large indoor spaces.

2023
- Renderable Neural Radiance Map for Visual NavigationObin Kwon, Jeongho Park, and Songhwai OhIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2023 (Highlight)Scene RepresentationVisual NavigationNeRF
We propose a novel type of map for visual navigation, a renderable neural radiance map (RNR-Map), which is designed to contain the overall visual information of a 3D environment. The RNR-Map has a grid form and consists of latent codes at each pixel. These latent codes are embedded from image observations, and can be converted to the neural radiance field which enables image rendering given a camera pose. The recorded latent codes implicitly contain visual information about the environment, which makes the RNR-Map visually descriptive. This visual information in RNR-Map can be a useful guideline for visual localization and navigation. We develop localization and navigation frameworks that can effectively utilize the RNR-Map. We evaluate the proposed frameworks on camera tracking, visual localization, and image-goal navigation. Experimental results show that the RNR-Map-based localization framework can find the target location based on a single query image with fast speed and competitive accuracy compared to other baselines. Also, this localization framework is robust to environmental changes, and even finds the most visually similar places when a query image from a different environment is given. The proposed navigation framework outperforms the existing image-goal navigation methods in difficult scenarios, under odometry and actuation noises. The navigation framework shows 65.7% success rate in curved scenarios of the NRNS dataset, which is an improvement of 18.6% over the current state-of-the-art. Project page: https://rllab-snu.github.io/projects/RNR-Map/
-
 Attention-Based Randomized Ensemble Multi-Agent Q-LearningJeongho Park, Obin Kwon, and Songhwai OhIn 2023 23rd International Conference on Control, Automation and Systems (ICCAS), Jun 2023Multi-AgentReinforcement Learning
Attention-Based Randomized Ensemble Multi-Agent Q-LearningJeongho Park, Obin Kwon, and Songhwai OhIn 2023 23rd International Conference on Control, Automation and Systems (ICCAS), Jun 2023Multi-AgentReinforcement LearningCooperative multi-agent scenarios are prevalent in real-world applications. Optimal coordination of agents requires appropriate task allocation, considering each task’s complexity and each agent’s capability. This becomes challenging under decentralization and partial observability, as agents must self-allocate tasks using limited state information. We introduce a novel multi-agent environment in which effective sub-task assignment is crucial for high-scoring performance. In addition, we propose a new multi-agent reinforcement learning framework named as attention-based randomized ensemble multi-agent Q-learning, or AREQ for short. This approach integrates a unique network structure using a multi-head attention mechanism, efficiently extracting task-related information from observations. AREQ also incorporates a randomized ensemble method, enhancing sample efficiency. We explore the impact of this attention-based structure and the random ensemble method through an ablation study and show AREQ’s superiority compared to existing MARL methods within our proposed environment.

2022
- Topological Semantic Graph Memory for Image-Goal NavigationNuri Kim, Obin Kwon, Hwiyeon Yoo, Yunho Choi, Jeongho Park, and Songhwai OhIn Proceedings of The 6th Conference on Robot Learning, 14–18 dec 2022 (Oral Presentation)Scene RepresentationVisual NavigationMemory BuildingImitation LearningReinforcement Learning
A novel framework is proposed to incrementally collect landmark-based graph memory and use the collected memory for image goal navigation. Given a target image to search, an embodied robot utilizes semantic memory to find the target in an unknown environment. In this paper, we present a topological semantic graph memory (TSGM), which consists of (1) a graph builder that takes the observed RGB-D image to construct a topological semantic graph, (2) a cross graph mixer module that takes the collected nodes to get contextual information, and (3) a memory decoder that takes the contextual memory as an input to find an action to the target. On the task of an image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths. Additionally, we demonstrate our method on a mobile robot in real-world image goal scenarios.
- Visually Grounding Language Instruction for History-Dependent ManipulationHyemin Ahn, Obin Kwon, Kyungdo Kim, Jaeyeon Jeong, Howoong Jun, Hongjung Lee, Dongheui Lee, and Songhwai OhIn 2022 International Conference on Robotics and Automation (ICRA), 14–18 dec 2022ManipulationMemory BuildingLanguage Instruction
2021
- Image-goal navigation algorithm using viewpoint estimationObin Kwon, and Songhwai OhIn International Conference on Control, Automation and Systems (ICCAS), 14–18 dec 2021Visual NavigationReinforcement Learning
This paper tackles the image-goal navigation problem, in which a robot needs to find a goal pose based on the target image. The proposed algorithm estimates the geometric information between the target pose and the current pose of the robot. Using the estimated geometric information, the navigation policy predicts the most appropriate actions to reach the target pose. We evaluated our method using the Habitat simulator with the Gibson dataset, which provides photo-realistic indoor environments. The experimental results show that adding an ability to estimate the geometric information helps the agent find the target pose much more successfully and time-efficiently. Furthermore, we investigate how this estimation ability affects navigation performances through various experiments.
-
 Geometric Understanding of Reward Function in Multi-Agent Visual ExplorationMinyoung Hwang, Obin Kwon, and Songhwai OhOct 2021Multi-AgentReinforcement LearningVisual Navigation
Geometric Understanding of Reward Function in Multi-Agent Visual ExplorationMinyoung Hwang, Obin Kwon, and Songhwai OhOct 2021Multi-AgentReinforcement LearningVisual NavigationReward shaping has proven to be a powerful tool to improve an agent’s performance in single agent reinforcement learning. Recently, this method has also been applied in multi-agent reinforcement learning. In this paper, we focus on the visual exploration task; a time-efficient way to explore novel environments as much as possible. To solve this problem, we present a new reward shaping method for multi-agent visual exploration with geometric understanding. We set the network baseline as a batched actor-critic model based on the PPO algorithm and shaped the reward function. In our method, mutual-overlapping and self-overlapping rewards are designed to improve the performance. Mutual-overlapping reward calculates re-explored areas using the inclusion-exclusion principle, and self-overlapping reward is calculated using the geodesic distance function between positions. We trained and evaluated six types of models with different reward functions in photo-realistic Habitat simulator and Gibson dataset. Experiment results show that the linearly modeled mutual-overlapping reward function enhances the coverage performance and saves total timesteps spent for exploration. Furthermore, we achieved the highest performance; covered ratio 81.8% and total timesteps 322.352 when we used global and local self-overlapping reward in addition to the linear mutual-overlapping reward.
- Visual Graph Memory With Unsupervised Representation for Visual NavigationObin Kwon, Nuri Kim, Yunho Choi, Hwiyeon Yoo, Jeongho Park, and Songhwai OhIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2021Visual NavigationScene RepresentationMemory BuildingImitation LearningReinforcement Learning
We present a novel graph-structured memory for visual navigation, called visual graph memory (VGM), which consists of unsupervised image representations obtained from navigation history. The proposed VGM is constructed incrementally based on the similarities among the unsupervised representations of observed images, and these representations are learned from an unlabeled image dataset. We also propose a navigation framework that can utilize the proposed VGM to tackle visual navigation problems. By incorporating a graph convolutional network and the attention mechanism, the proposed agent refers to the VGM to navigate the environment while simultaneously building the VGM. Using the VGM, the agent can embed its navigation history and other useful task-related information. We validate our approach on the visual navigation tasks using the Habitat simulator with the Gibson dataset, which provides a photo-realistic simulation environment. The extensive experimental results show that the proposed navigation agent with VGM surpasses the state-of-the-art approaches on image-goal navigation tasks.
-
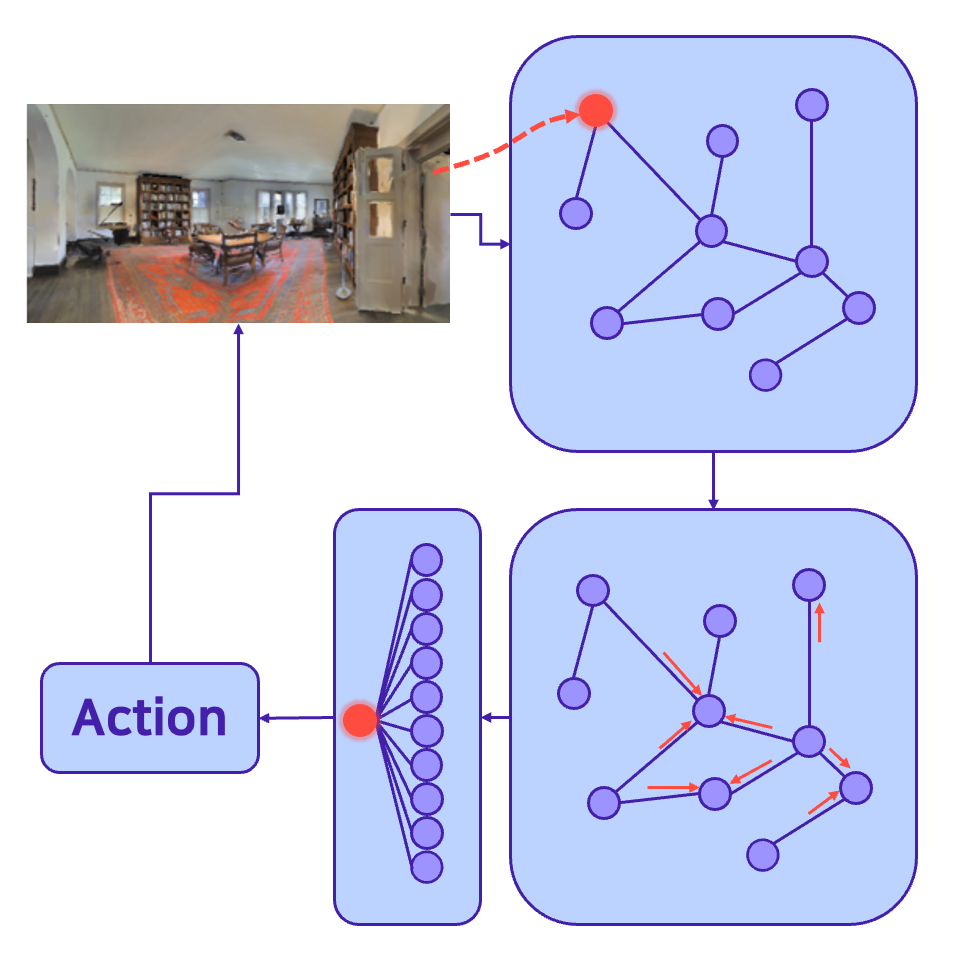 Image-Goal Navigation Algorithm using Viewpoint EstimationObin Kwon, and Songhwai OhIn 2021 21st International Conference on Control, Automation and Systems (ICCAS), Oct 2021Visual NavigationMemory BuildingReinforcement Learning
Image-Goal Navigation Algorithm using Viewpoint EstimationObin Kwon, and Songhwai OhIn 2021 21st International Conference on Control, Automation and Systems (ICCAS), Oct 2021Visual NavigationMemory BuildingReinforcement LearningThis paper tackles the image-goal navigation problem, in which a robot needs to find a goal pose based on the target image. The proposed algorithm estimates the geometric information between the target pose and the current pose of the robot. Using the estimated geometric information, the navigation policy predicts the most appropriate actions to reach the target pose. We evaluated our method using the Habitat simulator with the Gibson dataset, which provides photo-realistic indoor environments. The experimental results show that adding an ability to estimate the geometric information helps the agent find the target pose much more successfully and time-efficiently. Furthermore, we investigate how this estimation ability affects navigation performances through various experiments.

